In this section, we present performance data for Version 1.4 of ScaLAPACK on four distributed memory computers and two networks of workstations. The four distributed memory computers are the Cray T3E computer, the IBM Scalable POWERparallel 2 computer, the Intel XP/S MP Paragon computer, and the Intel ASCI Option Red Supercomputer. One of the networks of workstations consists of Sun Ultra Enterprise 2 (Model 2170s) connected via switched ATM. The other network of workstations, the Berkeley NOW [34] , consists of 100+ Sun UltraSPARC-1 workstations and 40+ Myricom crossbar switches and LANai 4.1 network interface cards. ScaLAPACK on the NOW uses MPI BLACS, where the MPI is a port of the freely-available MPICH reference code. MPI uses Active Messages as its underlying communications layer. Active Messages [98] provide ultra-lightweight remote-procedure calls for processes on the NOW. The system currently uses AM-II , a generalized active message layer that supports more than SPMD parallel programs, e.g., client-server programs and distributed filesystems. It retains the simple request/response paradigm common to all previous active message implementations as well as its high-performance. These six computers are a collection of processing nodes interconnected via a network. Each node has local memory and one or more processors. Tables 5.2, 5.3, and 5.4 describe the characteristics of these six computers.
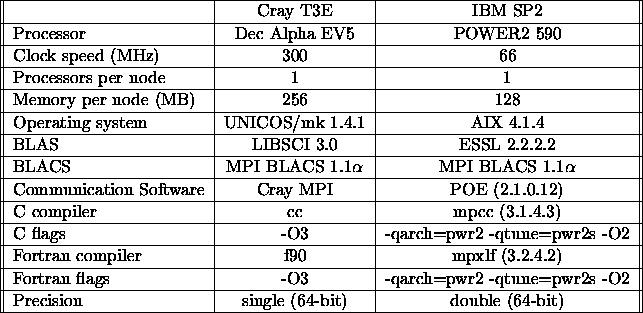
Table 5.2: Characteristics of the Cray T3E and IBM SP2 computers timed
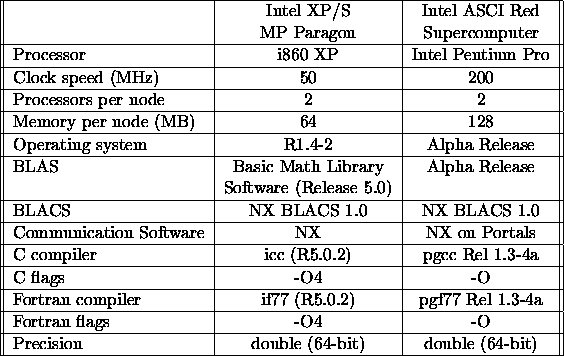
Table 5.3: Characteristics of the Intel computers timed
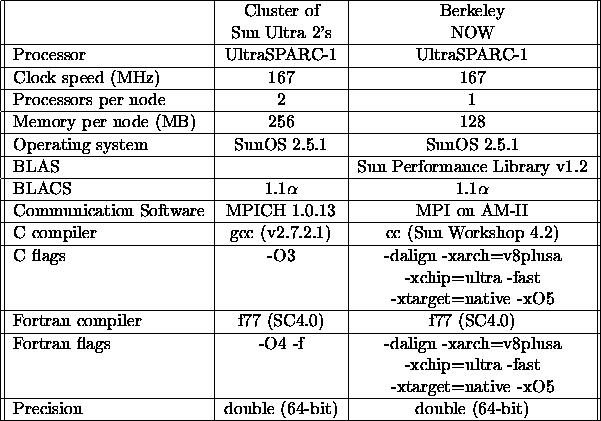
Table 5.4: Characteristics of the networks of workstations timed
As noted in Tables 5.2, 5.3, and 5.4,
a machine-specific optimized BLAS
implementation was used for all the performance numbers reported
in this chapter. For the IBM Scalable POWERparallel 2 (SP2)
computer, the IBM Engineering and Scientific Subroutine Library (ESSL)
was used [88]. On the Intel XP/S MP Paragon computer, the Intel
Basic Math Library Software (Release 5.0) [89] was used.
The Intel ASCI Option Red Supercomputer was tested using
a pre-alpha version of the Cougar operating system and using an
unoptimized functional version of the dual processor Basic Math Library from
Kuck and Associates, Inc. The communication performance and library
performance was still being enhanced.
On the Sun Ultra Enterprise 2
workstation, the Dakota Scientific Software Library (DSSL)![]() was used. The DSSL BLAS implementation used only one processor
per node. On the Berkeley NOW, the Sun Performance Library, version
1.2, was used. It should also be noted that for the IBM Scalable
POWERparallel 2 (SP2) the communication layer used was the IBM
Parallel Operating Environment (POE), which is a combination of
MPI and MPL libraries.
was used. The DSSL BLAS implementation used only one processor
per node. On the Berkeley NOW, the Sun Performance Library, version
1.2, was used. It should also be noted that for the IBM Scalable
POWERparallel 2 (SP2) the communication layer used was the IBM
Parallel Operating Environment (POE), which is a combination of
MPI and MPL libraries.
Several data distributions were tried for N=2000. The fastest data distribution for N=2000 was used for all problem sizes, although this data distribution may not be optimal for all problem sizes. Whenever applicable, only the options UPLO=`U' and TRANS=`N' were timed. The test matrices were generated with randomly distributed entries. All runtimes are reported in seconds. Block size is denoted by NB.
This section first reports performance data for a relevant selection of BLAS and BLACS routines. Then, timing results obtained for some PBLAS routines are presented. Finally, performance numbers for selected ScaLAPACK driver routines are shown.