|
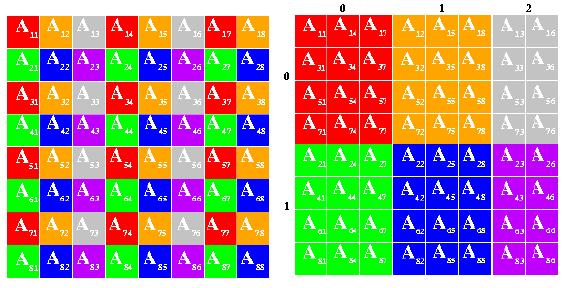
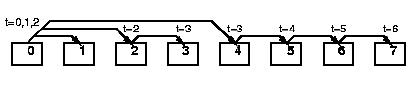
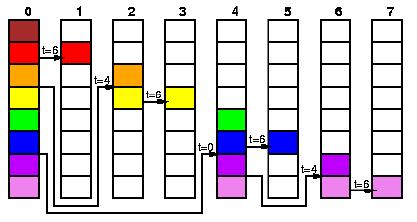
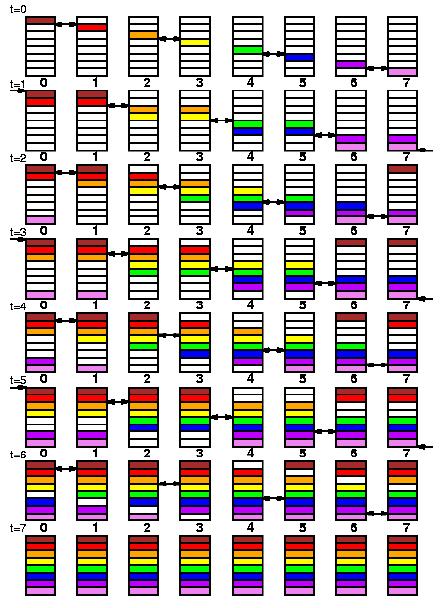
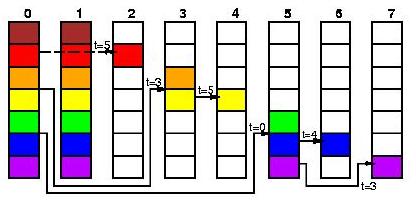
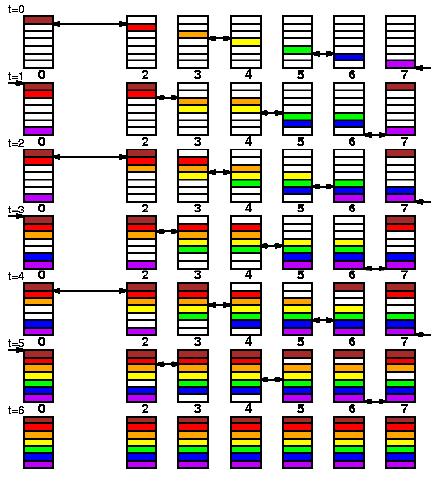
At a given iteration of the main loop, and because of the cartesian
property of the distribution scheme, each panel factorization occurs in
one column of processes. This particular part of the computation lies
on the critical path of the overall algorithm. The user is offered the
choice of three (Crout, left- and right-looking) matrix-multiply based
recursive variants. The software also allows the user to choose in how
many sub-panels the current panel should be divided into during the
recursion. Furthermore, one can also select at run-time the recursion
stopping criterium in terms of the number of columns left to factorize.
When this threshold is reached, the sub-panel will then be factorized
using one of the three Crout, left- or right-looking matrix-vector based
variant. Finally, for each panel column the pivot search, the associated
swap and broadcast operation of the pivot row are combined into one
single communication step. A binary-exchange (leave-on-all) reduction
performs these three operations at once. |
 |